At C4DM, we are organising a seminar/tutorial series about statistics aimed at graduate students (and ourselves). We will address persistent and fundamental questions we all have when we go about collecting and/or analysing data. Which statistical test should I use and why? How many subjects/observations do I need? Can I get away with 20? What can I validly conclude? There is a massive literature about statistics (it is one of the greatest achievements of the 20th century), but it will remain opaque as long as its fundamentals are absent in the training of researchers.
My tutorial on Dec. 15 will focus on why experimental design is central to answering these common questions. Just plugging one’s data into statistical packages and comparing p-values before considering the data collection is as senseless as shelling a clam after eating it. To demonstrate this, consider the following scenario:
As the local data science experts, we are contacted by a local chapter of oenophiles eager to have their data analysed in order to create an official ranking of local wines. They send us the table of results below with the description: “Four professional judges tasted four wines and scored each on a scale 1-5 (poor to excellent). Which wine is the best, and which is the worst, according to these judges? kthxbai!”
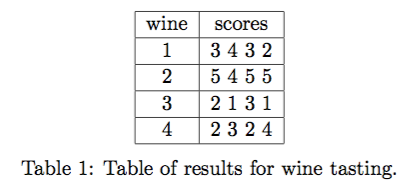
Let’s begin with some basic analysis.
We start by computing some descriptive statistics of each wine from Table 1: mean 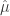

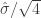
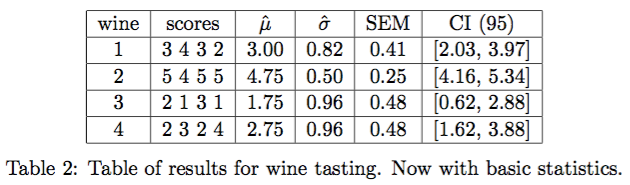
Wine 2 could have the highest mean score, wine 3 could have the lowest, and wines 1 and 4 are somewhere in the middle. Are these significant? Assuming each mean is distributed Normal, but with unknown variance, we compute its 95% confidence interval (CI, 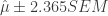

We see from this that we might conclude at a significance level 

We cannot conclude, however, that the mean scores of the other wines are significantly different from each other. Our estimated mean scores of wines 1 and 4 are higher than that of wine 3, but this could be due to chance. There are no clear losers, in other words.
A serious question to consider is how our analysis is impacted by the fact that the measurements are restricted to be integers in [1, 5]. No doubt, we could apply a variety of different tests, depending on the different ways we define “best” and “worst”; but doing so is jumping the gun because we haven’t considered the most important question first: What can we validly conclude from the results in Table 1?
I will show that in fact nothing can be concluded about these wines, no matter the scores in Table 1, because (SPOILER ALERT) the experimental design that led to its creation is “messed up.” In more general terms, I will show how the meaningful analysis of this data actually turns on the way the data was collected in the first place — the experimental design. This will demonstrate how “which statistical test to use and why” can be sensibly answered only after considering the experimental design.

Pingback: The centrality of experimental design, part 2 | High Noon GMT
Pingback: The centrality of experimental design, part 3 | High Noon GMT
Pingback: The centrality of experimental design, part 4 | High Noon GMT
Pingback: The centrality of experimental design, part 5 | High Noon GMT
I just discovered this series of posts, and I’d like to add my two cents when appropriate, if I may. Please, forgive me if I comment on something seen in the following posts. By the way, very glad to hear that you guys are planning these tutorials. I just wish it was more the rule than the exception!
a) Looks like data was gathered on ordinal scale, so the median is probably more appropriate.
b) It is mentioned that we compute the unbiased standard deviation, but running the numbers it looks like the square of the unbiased variance. However, this is not an unbiased standard deviation (Jensen’s inequality). One should use the so-called c4 correction factor: https://en.wikipedia.org/wiki/Unbiased_estimation_of_standard_deviation
c) The t-score to compute the confidence interval corresponds to the 0.05 quantile, but since this is on both sides, this is actually a 90% confidence interval. One should use quantiles 0.025 and 0.975: mu +/- 3.182446*SE.
d) I’m curious as to how the p-values in Table 3 were computed using ANOVA. Can you please explain or provide code? I tried ANOVA on each pair and t-tests, but numbers don’t match.
Off to post two!
LikeLike
Thanks Julian. There are many approaches to analysing the results of the experiment; however, as you see from the rest of the series, it is essential to first consider the central question of how exactly the data was collected.
b) I compute the SEM using “sqrt(var(dataset(jj,:)))”.
c) Ooops! You are right.
d) Just used the following code (until later on when I use eq. 23 with the assumed DoF):
dataset = [3 4 3 2; …
5 4 5 5; …
2 1 3 1; …
2 3 2 4];
[p,tab,stats] = anova1(dataset’);
[c,m,h,nms] = multcompare(stats);
LikeLike