In part 1, I review the MusiCNN system, and in part 2 I review the architecture of the “spectrogram”-based model trained on 3-second audio segments. In part 3, I look at how the input to MusiCNN is computed from an audio signal. In part 4 I begin to look at the first layer (CNN_1) of MusiCNN – in particular the 153 one-dimensional convolutions and their impact on an input dB Mel spectrogram. In part 5 I inspect the 408 two-dimensional convolutions in CNN_1. Part 6 looks at what the bias and activations of CNN_1 do to these 561 filtered versions of the input normalized dB Mel spectrogram. Part 7 looks at the normalization layer just after CNN_1. Part 8 looks at the final portion of the first stage, which reduces all the time-series created so far into one 561-dimensional time series – which is the input into the second stage. Part 9 then puts this all together: for MusiCNN trained in MSD, the maximum (anti-)correlations of the dB Mel spectrogram with only 62 specific time and time-frequency structures is what leads to the weights the system assigns to 50 specific tags. Part 10 looks at the processing of the output of CNN_1 by a layer of convolutions, CNN_2, followed by a normalization procedure. And part 11 looks at the processing of the output of CNN_2 by a layer of convolutions, CNN_3, followed by a normalization procedure and a skip connection. Now we move on to the next part of the system. We are here:

CNN_4 is the last convolutional layer of MusiCNN. As for the previous two convolutional layers, it consists of 64 units each having a kernel of size 64×7, a bias parameter, and the rectified linear activation function. Here’s the Frobenius norms of all CNN_4 kernels for MusiCNN trained in MSD and MTT:

It appears all 64 kernels are non-trivial for MTT CNN_4, and all but one of 64 for MSD CNN_4. Here’s what the 63 MSD CNN_4 kernels look like, ordered left to right by decreasing Frobenius norm:

We see that the output of all MSD CNN_2 and MSD CNN_3 units are weighted by these kernels. None are being ignored at this stage. Let’s have a look at specific outputs of MSD CNN_4 units compared with the dB Mel spectrogram of the input, our excerpt of GTZAN Disco Duck. Units 44 and 48 look quite active.


Units 1 and 60 appear sparse:


Concatenating these 64 time-series creates the output matrix 

Units 5 and 33 appear to be take on a consistently high value. Here’s what the time-series look like, showing high means:


After CNN_4, each of the output time series are normalized, as done for the output of CNN_3. Here’s the distribution of parameters for this normalization layer of MSD MusiCNN:

Just as a reminder, these parameters appear as so:
![[\hat{\mathbf{V}_3}]_{m,n} = \beta_m + \gamma_m \frac{[\mathbf{V}_3]_{m,n} - \mu_m}{\sqrt{\sigma_m^2+\epsilon}}](https://s0.wp.com/latex.php?latex=%5B%5Chat%7B%5Cmathbf%7BV%7D_3%7D%5D_%7Bm%2Cn%7D+%3D+%5Cbeta_m+%2B+%5Cgamma_m+%5Cfrac%7B%5B%5Cmathbf%7BV%7D_3%5D_%7Bm%2Cn%7D+-+%5Cmu_m%7D%7B%5Csqrt%7B%5Csigma_m%5E2%2B%5Cepsilon%7D%7D&bg=ffffff&fg=323232&s=0&c=20201002)
All 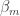
Here’s what the normalized matrix 

Curiously, the smallest value we see in
Overlaying

What does it mean? I don’t know. But at this point, MusiCNN will add 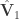


The color scale on is set to [0,10]. We see

The energies of the time series (l2-norm squared of each row) are computed with reference to the highest energy of a time series from CNN_2, i.e., of
The addition of these three matrices produces $\hat{\mathbf{V}}_1+\hat{\mathbf{V}}_2+\hat{\mathbf{V}}_3$, which is shown below:

where the color map is -10 to 10. The maximum value we see is almost 125 and the minimum is -17. So this is not a sparse matrix. If we sort all the values in each row, and then subtract the minimum value, and then divide by the maximum value of the result, we get the following image:

We see of all rows in this sum, only 5, 33 and 59 show a lot of activity; and 3, 29 and 53 show very little activity. I don’t know what this means yet.
We now reach the output of the second stage of MusiCNN: the concatenation of 


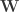
It is time to analyze the final stage of MusiCNN and hopefully unlock the significance of each of these time series!

Thank you for sharing your thought and analysis. It is an awesome write-up; by breaking it down to this extend, I wonder how would you have designed the preprocessing step better ?! In other words, could you come with a better protocol when it comes to do preprocessing ! I
LikeLike