The last four parts have analyzed our data using ANOVA with plots as judge-quality-replicates mapped to transcriptions as treatments. The Hasse diagrams built from the equivalence classes were:

The resulting ANOVA table for both the balanced and unbalanced designs (where N=430 and not 500) shows significant differences between levels at all factors. Here it is for the unbalanced design:
df sum_sq mean_sq F PR(>F)
T 24.0 202.144574 8.422691 12.590690 2.096389e-35
J 3.0 16.675775 5.558592 8.309282 2.283125e-05
Q 4.0 170.465116 42.616279 63.705103 2.522982e-41J ∧ Q12.0 51.623195 4.301933 6.430760 1.871955e-10
E 386.0 258.219246 0.668962 --- ---
Now let’s look at another way to see the experiment: transcriptions are the experimental units, the crossing of transcription, quality and replicate factors are the observational units (plots), and the judges are treatments. Below is the Hasse diagram of the plot structure (left) and treatment structure (right) of this view:

This shows how the crossing of transcription, quality and replicate factors results in a residual subspace with fewer dimensions (degrees of freedom). Since we only have 430 responses, the degrees of freedom will actually be 302 for the unbalanced design and 282 for the balanced design. The abbreviated response model for this experimental design is
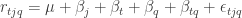
where 
df sum_sq mean_sq F PR(>F)J 3.0 18.589379 6.196460 7.625400 6.255522e-05 T 24.0 200.230970 8.342957 10.266893 4.440556e-27 Q 4.0 170.465116 42.616279 52.443846 1.616860e-33T ∧ Q96.0 64.434884 0.671197 0.825979 8.652560e-01 E 302.0 245.407558 0.812608 --- ---
From this we can see there are significant differences between the levels of the judge factors. Furthermore, we see that we are not able to reject the null hypothesis that there is no significant differences between the levels of the interaction between transcription and quality factors. We can thus interpret the statistics for those individual factors to reject the null hypotheses that there are no significant differences between the levels of those factors. These conclusions do not change with the balanced design.
Yet another way to see the experiment is with the following plot and treatment structures:

Now the treatments are created by crossing the T and Q factors, and the plots are created from crossing J, Q and the replicate factors. In this case, the experimental design maps a replicate of a judge-quality pair to a particular transcription-quality pair with shared qualities. The response model in this case is:
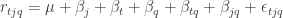
Here’s the resulting ANOVA table for the unbalanced design:
df sum_sq mean_sq F PR(>F)J 3.0 18.589379 6.196460 9.156495 8.292502e-06 T 24.0 200.230970 8.342957 12.328369 7.101300e-32 Q 4.0 170.465116 42.616279 62.973982 2.917260e-38T ∧ Q96.0 64.434884 0.671197 0.991826 5.084800e-01J ∧ Q12.0 49.156337 4.096361 6.053184 1.846294e-09 E 290.0 196.251221 0.676728 --- ---
The effects from the interaction of quality and transcription factors still do not appear significantly different, however we see significance in the interaction between judge and quality factors. Thus, we can conclude from this design:
- There is a significant difference between the transcriptions.
- There is a significant difference in the interactions between judge and quality.
We have looked at three possible ways to structure the plots and treatments. There are other possibilities. One is to see quality as the treatment applied to transcription-judge-replicate. The response model for this is:
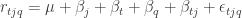
The ANOVA table in this case is:
df sum_sq mean_sq F PR(>F)Q 4.0 170.465116 42.616279 66.001059 2.827769e-41 J 3.0 18.589379 6.196460 9.596636 4.247538e-06 T 24.0 200.230970 8.342957 12.920978 5.475184e-35J ∧T 72.0 97.261449 1.350853 2.092106 6.199162e-06 E 340.0 219.534884 0.645691 --- ---
The interpretation of this model is focused on the effect of quality, and now we can conclude:
- There is a significant difference between the levels of quality.
- There is a significant difference between the levels of the interaction between judge and transcription.
Yet another possibility is the response model
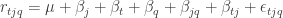
This considers interactions between tune and judge factors, and judge and quality factors. Here’s the ANOVA table:
df sum_sq mean_sq F PR(>F)T 24.0 202.144574 8.422691 16.452949 6.112975e-43 J 3.0 16.675775 5.558592 10.858197 8.083790e-07 Q 4.0 170.465116 42.616279 83.246972 1.032476e-48J ∧Q 12.0 51.623195 4.301933 8.403429 6.946644e-14J ∧T 72.0 95.499713 1.326385 2.590971 5.883618e-09 E 328.0 167.911688 0.511926 --- ---
In this case, we can conclude:
- There is a significant interaction between judge and quality.
- There is a significant interaction between judge and transcription.
But what is the treatment in this case?
Why not include all possible interactions, such as this model?

Here’s the ANOVA table:
df sum_sq mean_sq F PR(>F)T 24.0 202.144574 8.422691 18.444371 3.786772e-41 J 3.0 16.675775 5.558592 12.172444 1.995313e-07 Q 4.0 170.465116 42.616279 93.322965 3.542061e-47T ∧Q 96.0 64.434884 0.671197 1.469815 1.019657e-02J ∧Q 12.0 49.156337 4.096361 8.970389 4.385814e-14T ∧J 72.0 97.649035 1.356237 2.969945 3.033605e-10 E 232.0 105.943663 0.456654 --- ---
Curiously, we see here all interactions are significant. Even the interaction between transcription and quality is now significant, whereas in all other models we include this interaction we could not reject the null hypothesis. (The conclusions are the same for the balanced design.)
The reason for this is that the last model results in the smallest dimension of the residual subspace (232) and thus smallest squared error (106), while the projection of the responses into the orthogonal subspace of the cross of T and Q remains the same. More of the response is explained by the model.
Here’s a plot of the residual density, which shows a peakier distribution than a Gaussian:

Here are the prediction-residual plots:


Aside from the playable rating (where almost all values observed are 4 and 5), the fit is very good overall. But the interpretation of the model is not clear.
In the next part we will consider yet other possible models of the experiment!

Pingback: Modeling the 2020 AI Music Generation Challenge ratings, pt. 6 | Folk the Algorithms